

HDFS estimates the network bandwidth between two nodes by their distance. The distance from a node to its parent node is assumed to be one. A shorter distance between two nodes means that the greater bandwidth they can utilize to transfer data.
The placement of replica is critical to HDFS data reliability and read/write performance. A good replica placement policy should improve data reliability, availability and network bandwidth utilization. Currently HDFS provides a configurable block placement policy interface so that the users and researchers can experiment and test any policy that’s optimal for applications.
The default HDFS block placement policy tries to maintain a tradeoff between minimizing the write cost and maximizing data reliability, availability and aggregate read bandwidth. Upon the creation of a new block, the first replica is placed on the node where the writer is located, the second and the third replicas on two different nodes in a rack different from first’s replica’s rack. The rest of the replicas are placed with the restriction that no more than one replica is placed at one node and no more than two replicas are placed in the same rack when the number of replicas is less than twice the number of racks.
Although Hadoop has become a state of the art framework for high performance computing to process data of the scale of Terabytes or even larger, it certainly does have some shortcomings. Large number of evidence has proved that applications can face several bottlenecks due to the lack of high network and disk I/O bandwidths. In the present day, the effect of bottlenecks caused by disk stack is more pronounced than that caused by CPU or memory performance for the data intensive applications. There are many reasons for the I/O performance bottlenecks problem. First is that the performance gap between processing power and I/O systems in cluster is widening rapidly. For an example, performance of processors has seen an annual increase of about 60% for the last two decades, whereas the overall performance improvement of disks has been fluctuating around an annual growth rate of about 7% within the same period. Second is the heterogeneity of various resources with in clusters makes the I/O bottleneck problem further pronounced.
HDFS places the first replica block onto the writer node always, if the node is in the cluster, and on a node with highest proximity otherwise. This scheme is responsible for making the cluster highly unbalanced in terms of data placement. In case the MapReduce does not leveraged by writer node, all the first replicas block would place on the writer node. Over a long course of run, this makes the writer node a hotspot.
Further analyzing the MapReduce layer it is interpreted that, it tries to execute copy of job on cluster nodes that have required data set available locally. Since generally the disk I/O is much faster than network I/O, thus travelling computation is much cheaper than travelling the data. As Hadoop has been into prominence for quite some time now, the hardware components have evolved since the early stages of Hadoop. The general implementation of HDFS does not consider this gap in generation of hardware components. Considering disk I/O, a job running on a new generation disk, such as faster SATA or Solid State Disks (SSDs), with twice as much I/O speeds shall be able to transfer twice as much as data on an older generation disk. If this gap in hardware technologies are given significant weights, it would surely play a vital role in the overall performance of the cluster.
New Approach
Th approach mentioned in this post below, tries to diminish the shortcomings mentioned above by suggesting an improvement in the Hadoop default Data Placement Policy. The proposed block placement policy consists of two major objectives which has been incorporated into a single algorithm. First, the new placement algorithm distributes blocks across all the DataNodes in the cluster evenly. Second, nodes hving higher I/O efficiency would handle more of data in order to improve the overall performance of the cluster.
Implementing the proposed technique for data placement instead of the default data placement policy of Hadoop is expected to increase the overall performance of the cluster.
In order to ensure that DataNodes with higher I/O speeds cater to relatively more data blocks and read/write requests as compared to those with relatively slow I/O speeds, a concept of weight and Quantum is introduced. Weight is the factor that denotes the relative processing power for a generation of hardware. Quantum is the maximum number of data blocks that can be placed on a node pertaining to a single replica of a file.
Let r be the replication factor of file in the cluster. Assuming that the file has been split into n blocks, the Quantum of each node can be calculated as follows:
| Quantum node = ceil ( n * weight node / weight total ) |
The below suggested algorithm is different from the HDFS default block placement algorithm in a way that it works on file level instead of the global list of blocks.
Algorithm:
- Let LIST node be the list of all the nodes in the
- Let LIST block be the list of all the blocks in a file Fi.
- Let Quantum node maintain the Quantum value, as defined above, for each node in the
- Sort Quantum block in decreasing order of Quantum value (higher Quantum nodes are given priority over lower Quantum nodes).
- Sort the nodes with equal Quantum value on the basis of disk utilization (lower disk utilization to be given higher priority).
- For each block of File Fi, do the following:
- Initialize the BLOCK_LIST unplaced with all the blocks of Fi.
- Set NODE_LIST avail with all the nodes in the cluster (sorted list).
- For each block in BLOCK_LIST unplaced perform the following:
- Let SEL_NODE be the first node in NODE_LIST avail that has not reached its Quantum and does not already contain a replica of this block.
- Place the block on SEL_NODE and remove it from block_list unplaced. Also remove SEL_NODE from NODE_LIST avail.
- If the NODE_LIST avail becomes empty at this point, reinitialize it with all the nodes (again, in sorted order as above)
Example:
The following example explains the implementation of the algorithm further.
Consider a file Fi consisting of 10 blocks ( i.e. n = 10). Also assuming there are two types of nodes in the cluster. 3 nodes having weight = 1 and also 3 nodes having weight = 2.
Therefore, the value of
Quantum newer = ceil (10* 2 / (1*3 + 2*3)) = 3
Quantum older = ceil (10* 1 / (1*3 + 2*3)) = 2
Hence, on the nodes with weight 2, a maximum of 3 blocks per file per replica can be placed whereas on nodes with weight 1 a maximum of 2 blocks per file per replica can be placed.
Assuming, the cluster is empty in the beginning. Let the sorted list of nodes be {P, Q, R, X, Y, Z} in order of decreasing Quantum, where {P, Q, R} are nodes with weight 2 and {X, Y, Z} are the nodes with weight 1. Let the block list of Fi be {1, 2, 3, 4, …, 10}. For the first replica (denoted by green color), the blocks can be evenly distributed across the cluster, as shown in the figure.
Starting from the first block of the second replica, the algorithm shows an improvement. At this point, nodes {Y, Z} have lower utilization than node {P}. Block 1 cannot be placed on node {P} as node {P} already has a replica of block 1. Hence block 1 is placed on node {Q}. For block 2, node {P} is a suitable node.
Continuing in this manner, the final placement of the blocks looks as shown in the below figure
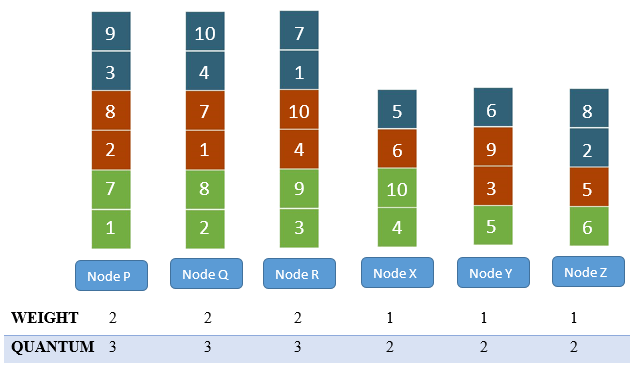
As it can be interpreted from the above figure that after every iteration, the nodes having higher weights have a tendency to store more blocks in comparison to those having lower weights. This effect could be seen more prominently, if the sample with larger number of nodes and large file is considered.

Reblogged this on SQL Tutorials.
LikeLike