

Pipelining is the technique used by HDFS to minimize inter-node network traffic. Whenever the first block replica is written by a to a node, then it’s the responsibility of that node to write the second replica to a random off-rack node. Further, it’s the responsibility of this off-rack node to write the third replica to a random node in the same rack.
The outcome of this pipelining is the reduction in network traffic of cluster because the job is responsibe of writing only one replica, instead of all the three replicas. Additionally, inter-rack traffic is also reduced as the node holding the second replica writes to a random in-rack node and does not cross rack-boundary.
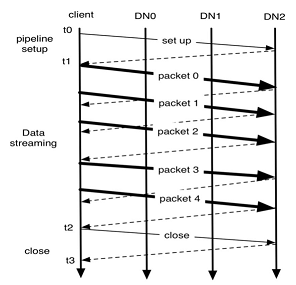
As shown in the figure above, block construction goes though three stages if no error occurs. In the figure, there are three DataNodes (DN0, DN1, DN2) and a block of five packets, acknowledgment messages are represented using dashed lines and the thin lines represent messages to setup and close the pipeline.
When a file is opened by a client to b read, it fetches the list of blocks and the locations of each block replica from the NameNode. The locations of each block are ordered by their distance from the reader. When reading a block, the client tries the closest replica first. A read may fail if the target node is unavailable, the node no longer hosts a replica of the block or the replica is found to be corrupt.
The design of the HDFS I/O is optimized for beach processing systems like MapReduce, which require high throughput for sequential reads and writes. However, many efforts have been put to improve the read/write response time on order to support real time data streaming to HDFS.

2 comments